LocoGen: Mechanistic Knowledge Localization
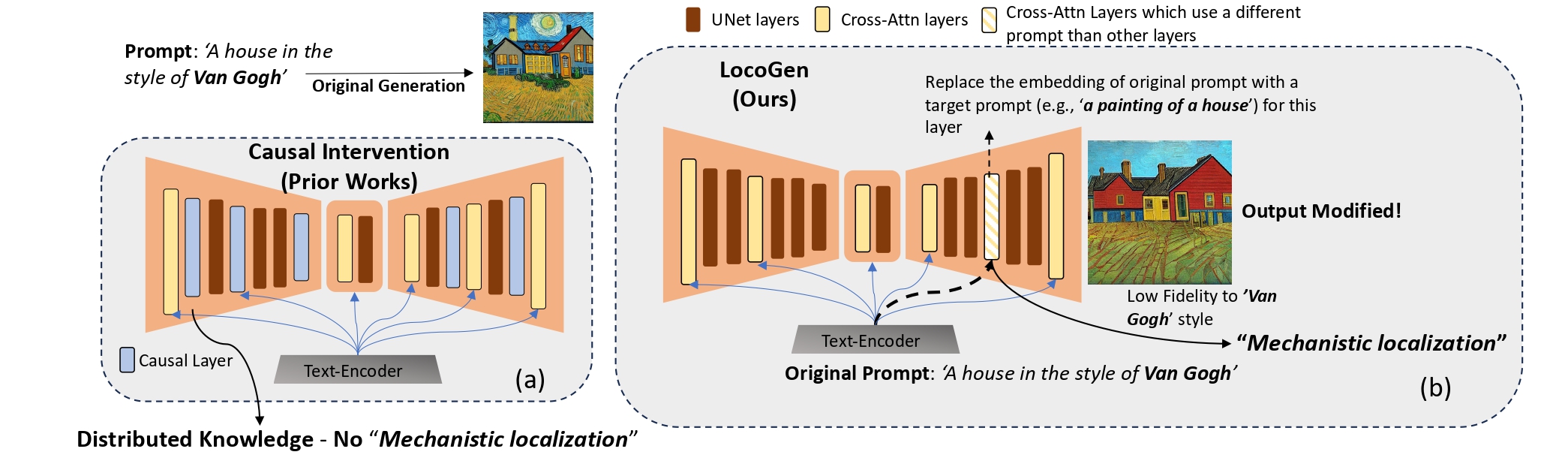
To address the universal knowledge localization framework absence across different text-to-image models, we introduce the concept of >mechanistic localization that aims to identify a small number of layers which control the generation of distinct visual attributes, across a spectrum of text-to-image models. To achieve this, we propose LocoGen, a method that finds a subset of cross-attention layers in the UNet such that when the input to their key and value matrices is changed, output generation for a given visual attribute (e.g., "style") is modified (see above Figure). This intervention in the intermediate layers has a direct effect on the output -- therefore LocoGen measures the direct effect of intermediate layers, as opposed to indirect effects in causal tracing.
LocoGen effectivley identifies important layers!

Images generated by intervening on the layers identified by LocoGen across various open-source text-to-image models. We compare the original generation vs. generation by intervening on the layers identified with LocoGen along with a target prompt. We find that across various text-to-image models, visual attributes such as style, objects, facts can be manipulated by intervening only on a very small fraction of cross-attention layers.
How does LocoGen find these layers?

To apply LocoGen for a particular attribute, we obtain a set of input prompts T that include the particular attribute and corresponding set of prompts T' where each prompt T'i there is analogous to a corresponding prompt Ti in T except that the particular attribute is removed/updated. These prompts serve to create altered images and assess the presence of the specified attribute within them. Let ci be the text-embedding of Ti and c'i be that of T'i. Given m (number of layers to consider) and M (number of total layers), we examine all M-m+1 possible candidates for controlling layers. For each of them, we generate N altered images where i-th image is generated by giving c'i as the input embedding to selected $m$ layers and ci to other ones. Then we measure the CLIP-Score of original text prompt Ti to the generated image for style, objects and target text prompt T'i$ to the generated image for facts. For style and objects, drop in CLIP-Score shows the removal of the attribute while for facts increase in score shows similarity to the updated fact. We take the average of the mentioned score across all 1 ≤ i ≤ N. By doing that for all candidates, we report the one with minimum average CLIP-Score for style, objects and maximum average CLIP-Score for facts. These layers could be candidate layers controlling the generation of the specific attribute. Above Algorithm provides the pseudocode to find the best candidate.
LocoEdit effectively edits the model!

LocoGen extracts the set of cross-attention layers that control specific visual attributes (e.g., style). We refer to this set as C_loc, a subset of cross-attention layers from which the knowledge about these attributes is influenced. Each layer contains value and key matrices, and the goal is to modify these matrices in a way that transforms the attention mechanism input from an original prompt (such as “A house in the style of Van Gogh”) to a target prompt (such as “A house in the style of a painting”). This adjustment affects how the visual attribute appears in the generated image.

In fact, we solve the above optimization problem where
- Xorig refers to the text-embeddings of original prompts -- having the artistic style, copyright object, or outdated knowledge;
- Xtarget refers to text-embeddings of target prompts -- including updated knowledge or lacking the visual attribute;
- Wlk that refers to key matrix in localized layer l;
- W^ lk that refers to key matrix in localized layer l.
Zero-Shot Model Editing is Possible!

As seen in above Figure, neuron-level modification at inference time is effective at removing styles. This shows that knowledge about a particular style can be even more localized to a few neurons. It is noteworthy that the extent of style removal increases with the modification of more neurons, albeit with a trade-off in the quality of generated images. This arises because modified neurons may encapsulate information related to other visual attributes.